
GaussDB(DWS)-Kerntechnologien
GaussDB(DWS) verwendet eine verteilte Shared-Nothing-Architektur, unterstützt hybride Zeilen-Spalten-Speicherung und ist hochverfügbar, zuverl?ssig, sicher und intelligent.
Shared-Nothing-Architektur
Jede GaussDB(DWS)-Datenbankinstanz (Datenknoten oder DN) verfügt über eine eigene CPU, einen eigenen Arbeitsspeicher und einen eigenen Speicher. Keine dieser Ressourcen wird gemeinsam genutzt.
Die Shared-Nothing-MPP-Architektur stellt den uneingeschr?nkten Zugriff auf CPU-, E/A- sowie Speicherressourcen sicher und die Leistung verbessert sich linear, wenn der Cluster horizontal skaliert wird, wodurch Daten bis zu Petabytes unterstützt werden.
Verteilte Speicherung
GaussDB(DWS) teilt Tabellen horizontal in Shards auf und verteilt Tupel auf Knoten basierend auf einer konfigurierten Verteilungsrichtlinie. In einer Abfrage k?nnen Sie unn?tige Daten herausfiltern und die ben?tigten Daten schnell finden.
GaussDB(DWS) partitioniert auch Tabellendaten in nichtüberlappende Bereiche.
Die Partitionierung bietet Ihnen die in der folgenden Tabelle beschriebenen Vorteile.
Tabelle 2-1 Vorteile der Partitionierung
|
Szenario
|
Leistung
|
|---|---|
Zeilen, auf die h?ufig zugegriffen wird, befinden sich entweder nur in einer oder in mehreren Partitionen. |
Der Suchbereich wird erheblich reduziert und die Zugriffsleistung verbessert. |
Die meisten Datens?tze einer Partition müssen abgefragt oder aktualisiert werden. |
Die Leistung wird erheblich verbessert, da nur die spezifischen Partitionen gescannt werden und nicht die gesamte Tabelle. |
Datens?tze, die in Batches geladen oder gel?scht werden müssen, befinden sich entweder nur in einer oder in mehreren Partitionen. |
Die Verarbeitungsleistung wird verbessert, da der Zugriff bzw. das L?schen nur auf wenigen Partitionen erfolgt. Sie k?nnen verstreute Vorg?nge vermeiden. |
Die Datenpartitionierung bietet folgende Vorteile:
- Bessere Verwaltbarkeit
Tabellen und Indizes sind in kleinere und besser verwaltbare Einheiten unterteilt. Dadurch k?nnen Datenbankadministratoren Daten basierend auf Partitionen verwalten. Die Wartung kann nur für bestimmte Teile einer Tabelle durchgeführt werden.
- Schnelleres L?schen
Das L?schen einer Partition ist schneller und effizienter als das L?schen von Zeilen.
- Schnellere Abfrage
Sie k?nnen den Umfang der zu prüfenden oder zu bearbeitenden Daten mit den folgenden Methoden eingrenzen:
- -Partitionsbereinigung:
Durch Bereinigung oder Eliminierung von Partitionen müssen weniger Partitionen von Coordinator Nodes (CNs) gescannt werden. Diese Funktion verbessert die Abfrageleistung erheblich.
- Partitionsweise Verbindung:
Partitionsweise Verbindungen k?nnen die Performance verbessern, wenn zwei Tabellen verknüpft werden und mindestens eine von ihnen auf dem Verbindungs-Schlüssel partitioniert ist. Partitionsweise Verbindungen teilen eine gro?e Verbindung in kleinere Verbindungen von ?identischen“ Datens?tzen auf. ?Identisch“ gibt an, dass die Gruppe der Partitionierungs-Schlüsselwerte auf beiden Seiten der Verbindung identisch ist. Nur diese Datens?tze werden für die Verbindung verwendet.
Vollst?ndig paralleles Computing
GaussDB(DWS) verwendet eine Reihe von verteilten Ausführungs-Engines, um die Ressourcen vollst?ndig zu nutzen und die Leistung zu maximieren.

Abbildung 2-1 GaussDB(DWS) vollst?ndig paralleles Computing
Die Kerntechnologien des vollst?ndig parallelen Computing von GaussDB(DWS), wie in der Abbildung oben dargestellt, sind:
- MPP: Knotenparallelit?t
Das verteilte Ausführungs-Framework mit VPP-User-Space-TCP-Protokoll erm?glicht es über 1.000 Servern, parallel mit Zehntausenden von CPUs zu arbeiten.
- Symmetrisches Multi-Processing (SMP): Parallelit?t des Operators
Eine SQL-Anweisung kann in viele Threads aufgeteilt werden, die parallel ausgeführt werden. Multikern-Prozessoren und Non-Uniform Memory Access (NUMA) k?nnen eingesetzt werden, um die Vorg?nge zu beschleunigen.
- Single Instruction Multiple Data (SIMD): Parallelit?t der Anweisungen
Eine x86- oder Arm-Anweisung kann für Datens?tze in Batches ausgeführt werden.
- Dynamische Kompilierung von Low Level Virtual Machine (LLVM)
Sie k?nnen LLVM verwenden, um Maschinencode anhand von Schlüsselfunktionen zu generieren, wodurch die für die SQL-Ausführung erforderlichen Anweisungen reduziert werden und die Verarbeitung beschleunigt wird.
Hybride Zeilen- und Spaltenspeicherung und vektorisierte Ausführung
In GaussDB(DWS) k?nnen Sie die Zeilen- oder Spaltenspeicherung für Ihre Tabelle verwenden, wie in der folgenden Abbildung dargestellt.

Abbildung 2-2 Hybride GaussDB(DWS)-Speicher-Engine für Reihen-Spalten
Mit der Spaltenspeicherung k?nnen Sie alte, inaktive Daten komprimieren, um Platz freizugeben und so die Kosten für Anschaffung und Betrieb und Wartung zu senken. Die Spaltenspeicher-Komprimierung von GaussDB(DWS) unterstützt Algorithmen wie Delta-Codierung, Dictionary-Komprimierung, RLE, LZ4 und ZLIB und kann automatisch Komprimierungsalgorithmen basierend auf Ihren Dateneigenschaften ausw?hlen. Die durchschnittliche Komprimierungsrate erreicht 7:1. Komprimierte Daten k?nnen ohne Dekomprimierung abgerufen werden und sind für Services transparent. Dadurch wird die Wartezeit für den Zugriff auf historische Daten erheblich reduziert.
Die vektorisierte Ausführung von GaussDB(DWS) kann mehrere Tupel gleichzeitig verarbeiten und so die Effizienz erheblich verbessern. Wenn Sie Zeilen- und Spaltenspeichertabellen gleichzeitig abfragen, kann GaussDB(DWS) automatisch zwischen Zeilen- und Spaltenspeicher-Engines wechseln, um eine optimale Leistung zu erzielen.
Hohe Prim?r-/Standby-/Sekund?r-Verfügbarkeit
In einem konventionellen System mit zwei Kopien, das aus einem Prim?r- und einem Standby-Server besteht, kann bei einem defekten Server der andere Server weiterhin Services bereitstellen, aber er kann nur eine Kopie der Daten behalten. Wenn der zweite Server ebenfalls ausf?llt, geht diese Kopie dauerhaft verloren. Sie k?nnen ein System mit drei Kopien bauen, um dieses Problem zu vermeiden, aber es kostet Sie mehr Speicherkapazit?t. Zur Senkung der Speicherkosten verfügt GaussDB(DWS) über prim?re, sekund?re und Standby-HA-Mechanismen. Selbst wenn ein Server defekt ist, sind noch zwei Datenkopien verfügbar. Dadurch wird im Grunde die gleiche Datenzuverl?ssigkeit wie beim Drei-Kopien-Mechanismus erreicht, aber mit nur 2/3 des ben?tigten Speichers.

Abbildung 2-3 Prim?r-/Standby-/Sekund?r-Replikation
Wie in dieser Abbildung dargestellt, stellt GaussDB(DWS) prim?re, sekund?re und Standby-Server bereit. Wenn sie ordnungsgem?? ausgeführt werden, führen die Prim?r- und Standby-Server eine starke Synchronisierung durch Protokoll-Streams und Datenseiten-Streams durch. Der prim?re Server stellt eine Verbindung zum sekund?ren Server her, sendet jedoch keine Protokolle oder Daten an diesen, sodass der sekund?re Server keine Speicherressourcen belegt. Wenn der Standby-Server ausf?llt, sendet der prim?re Server alle Protokolle und Daten, die nicht synchronisiert wurden, an den sekund?ren Server. Der prim?re Server startet dann eine starke Synchronisierung mit dem sekund?ren Server. Dieses Switchover wird in Kernels durchgeführt und wirkt sich nicht auf Transaktionen aus. Es treten keine Fehler oder Inkonsistenzprobleme auf.
Wenn der prim?re Server ausf?llt, stuft die Cluster-Verwaltungskomponente den Standby-Server auf den prim?ren Server hoch. Der neue prim?re Server startet eine starke Synchronisierung mit dem sekund?ren Server. Wenn einer der Datenknoten (DNs) in einer DN-Gruppe ausf?llt, sind auf diese Weise weiterhin zwei Datenkopien verfügbar, um die Datenzuverl?ssigkeit zu gew?hrleisten.
Horizontale Online-Skalierung
Ein GaussDB(DWS)-Cluster kann bis zu 2.048 Knoten enthalten. Seine Speicher- und Rechenkapazit?ten k?nnen linear durch das Hinzufügen von Knoten verbessert werden.
Die Node Group-Technologie von GaussDB(DWS) erm?glicht die parallele horizontale Skalierung mehrerer Tabellen mit einer Geschwindigkeit von bis zu 400 GB pro Stunde auf jedem neuen Knoten. Die folgende Abbildung zeigt den Prozess der horizontalen Skalierung.
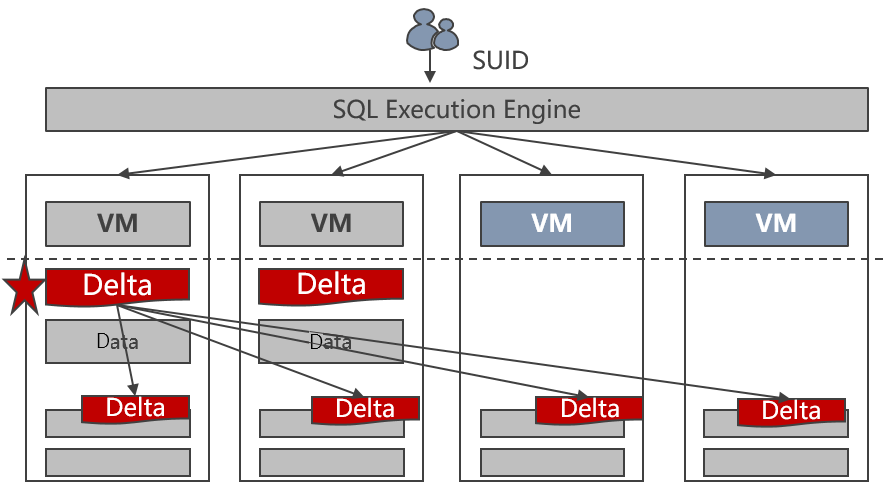
Abbildung 2-4 Prozess der horizontalen Skalierung
Die horizontale Skalierung von GaussDB(DWS) hat die folgenden Vorteile:
- Servicekontinuit?t
Datenimport und Abfragen werden w?hrend der horizontalen Skalierung nicht unterbrochen.
- Konsistentes Hashing und parallele horizontale Skalierung mit mehreren Tabellen
Konsistentes Hashing minimiert die Datenmenge, die w?hrend der Neuverteilung migriert werden muss.
Mehrere Tabellen k?nnen parallel verteilt werden. Sie k?nnen die Reihenfolge der Neuverteilung angeben.
Sie k?nnen den Fortschritt der Skalierung überprüfen.
- Lineare Steigerung der Leistung
GaussDB(DWS) verfügt über eine vollst?ndig parallel verteilte Architektur. Die Leistung beim Laden von Daten, die Verarbeitungsleistung des Service und die Speicherung eines Clusters nehmen linear zu, wenn Knoten hinzugefügt werden.
Transparente Sicherheit
GaussDB(DWS) unterstützt transparente Datenverschlüsselung. Das Benutzererlebnis wird durch die Verschlüsselung oder Entschlüsselung nicht beeintr?chtigt. Jedes Cluster verfügt über einen Cluster-Verschlüsselungsschlüssel (CEK). Jede Datenbank wird mit einem unabh?ngigen Datenbank-Verschlüsselungsschlüssel (DEK) verschlüsselt. Ein DEK wird mit einem CEK verschlüsselt, um die Sicherheit zu erh?hen. Sie k?nnen Kerberos verwenden, um Schlüssel zu beantragen, zu verschlüsseln und zu entschlüsseln und Verschlüsselungsalgorithmen über Konfigurationselemente auf einheitliche Weise zu konfigurieren. Derzeit werden AES- und SM4-Algorithmen unterstützt. Der SM4-Algorithmus unterstützt Hardwarebeschleunigung in Chips von Hi1620 und sp?teren Versionen.
Wir helfen Ihnen dabei, mit Big-Data-Analysen Mehrwert zu schaffen und gleichzeitig den Datenschutz zu schützen. Sie k?nnen Richtlinien definieren, um bestimmte Spalten zu maskieren und sensible Daten zu schützen. Nachdem eine Datenmaskierungs-Richtlinie wirksam wird, k?nnen nur der Administrator und der Tabelleneigentümer auf die Originaldaten zugreifen. Die Maskierung wirkt sich nicht auf die Datenverarbeitung aus. Maskierte Daten k?nnen weiterhin für die Berechnung verwendet werden. Die Daten werden nur maskiert, wenn die Datenbank Ergebnisse zurückgibt.
Die nachfolgende Abbildung zeigt ein Beispiel hierfür. Gehalt, E-Mail-Adresse und Mobiltelefonnummer der Mitarbeiter sind vertrauliche Daten. Diese Daten werden zum Schutz der Privatsph?re in x-Markierungen konvertiert.

Abbildung 2-5 Ergebnisse der Datenmaskierung
Für die Datenmaskierung werden folgende Schlüsseltechnologien verwendet:
- Benutzerdefinierter Geltungsbereich
Sie k?nnen DDL-Anweisungen ausführen, um Datenmaskierungs-Richtlinien auf bestimmte Spalten anzuwenden.
- Benutzerdefinierte Richtlinien
Sie k?nnen Datenmaskierungs-Funktionen basierend auf integrierten numerischen, Zeichen- und Zeittyp-Maskierungsfunktionen anpassen.
- Zugriffssteuerung
Nachdem die Daten maskiert wurden, k?nnen nur der Administrator und der Tabelleneigentümer die Daten sehen.
- Datenverfügbarkeit
Maskierte Daten k?nnen für die Berechnung verwendet werden, werden jedoch maskiert, wenn die Datenbank Ergebnisse zurückgibt.
SQL-Selbstdiagnose
Die konventionelle SQL-Leistungsoptimierung, insbesondere in verteilten Datenbanken, ist kompliziert und schwierig. Eine effektive Fehlersuche erfordert umfangreiche Fachkenntnisse und Erfahrung. GaussDB(DWS) analysiert Leistungsprobleme w?hrend der SQL-Ausführung intelligent und zeichnet diese auf leicht verst?ndliche Weise auf und pr?sentiert sie. Sie k?nnen ganz einfach lernen, wie Sie Ihre SQL-Anweisungen optimieren sollten, um die Leistung zu verbessern.
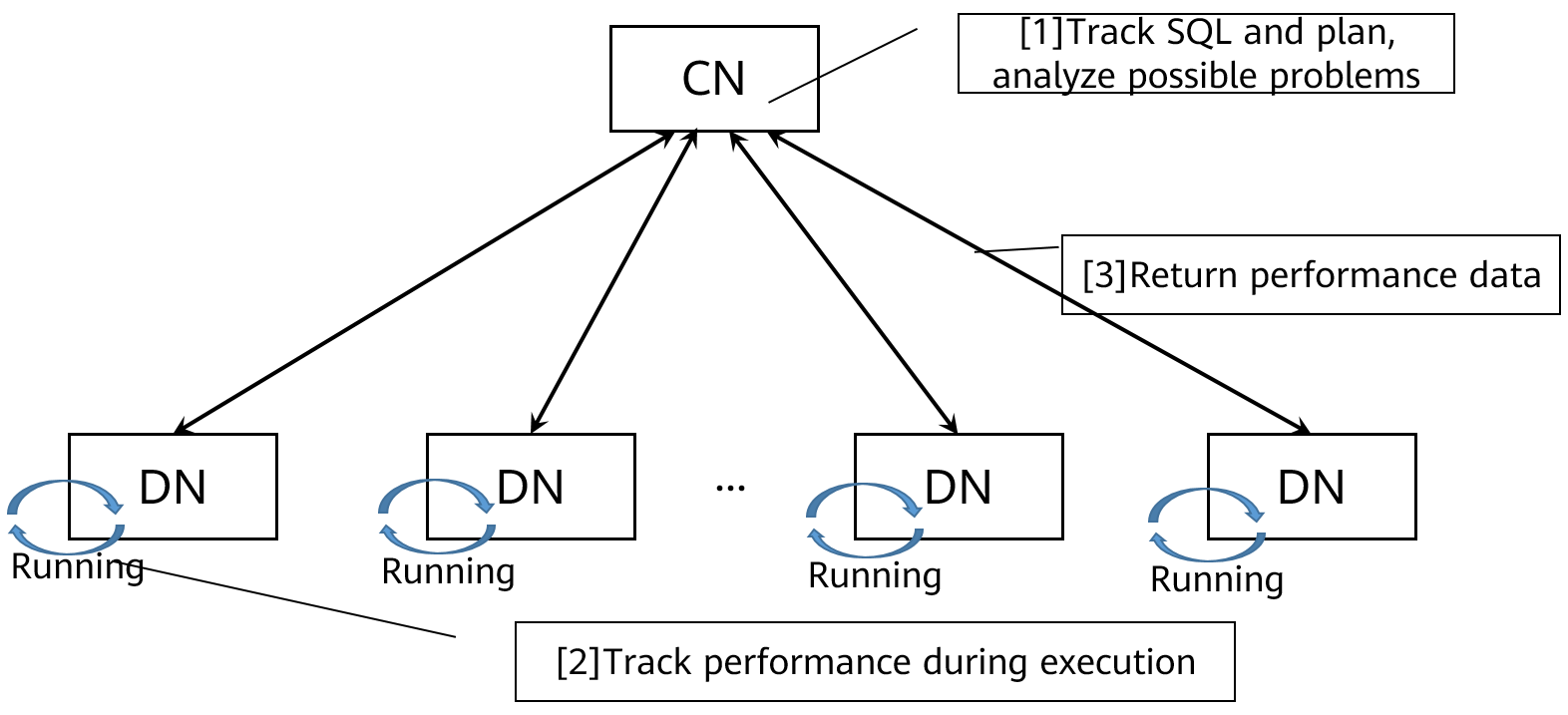
Abbildung 2-6 Funktionsweise der SQL-Selbstdiagnose